Build a Command-Line Text Analyzer in Python - Step by Step

Build a Command-Line Text Analyzer in Python that reads a text file, counts lines or words, displays frequent words, detect long lines.
Introduction
Whether you're a developer, writer, or student, analyzing text files can help uncover patterns and insights fast. Instead of doing it manually, why not build your own command-line text analyzer in Python?
In this guide, we'll build a tool that:
- Reads a text file
- Counts lines and words
- Displays frequent words
- Detects long lines
Let's dive in.
Prerequisites
- Python installed on your machine (3.6+ recommended).
- Create a new folder to keep the project related files in it. I'll name it as
command-line-text-analyzer. - Open the above newly created folder in Visual Studio Code (VSCode).
- Create a new file named
text-analyzer.py.
Step 1: Accept Command-Line Arguments
To analyze any file from the terminal, we need to accept its path and an optional max line length. We'll use argparse for this.
import argparse
def main():
parser = argparse.ArgumentParser(description="Command-line Text Analyzer")
parser.add_argument("file", help="Path to the text file")
parser.add_argument("--length", type=int, default=80, help="Max line length to check for long lines")
args = parser.parse_args()
print(f"Analyzing file: {args.file}")
print(f"Long line threshold: {args.length} characters")
if __name__ == "__main__":
main()
Explanation:
-
argparse.ArgumentParser() lets us define command-line arguments.
-
file is required; --length is optional (defaults to 80).
-
Run this with:
Terminalpython text-analyzer.py dummy_text_file.txt --length 100
Create a sample text files for testing. I am using dummy_text_file.txt with some random text and long_story.txt with multiple paragraphs.
Step 2: Read the File Safely
Let’s read the file contents into memory and handle missing file errors gracefully.
def read_file(filepath):
try:
with open(filepath, 'r', encoding='utf-8') as f:
return f.readlines()
except FileNotFoundError:
print(f"Error: File not found - {filepath}")
return []
Explanation:
- This reads all lines into a list.
- It uses UTF-8 encoding for compatibility.
- If the file doesn’t exist, it prints an error and returns an empty list.
Update main() to use it:
lines = read_file(args.file)
if not lines:
return
Step 3: Count Lines
This one’s easy! Just use len() on the list of lines.
def count_lines(lines):
return len(lines)
In main():
line_count = count_lines(lines)
print(f"Total lines: {line_count}")
Step 4: Count Words
We want to count all words, stripping punctuation so “hello!” becomes just “hello”.
import string
def count_words(lines):
words = []
for line in lines:
clean_line = line.translate(str.maketrans('', '', string.punctuation))
words.extend(clean_line.strip().split())
return len(words), words
Explanation:
str.maketrans('', '', string.punctuation)removes all punctuation.split()breaks the line into words.- We return:
- total word count
- list of all words (for frequency analysis)
Step 5: Analyze Word Frequency
We’ll use collections.Counter to tally up word counts.
from collections import Counter
def word_frequencies(words):
return Counter(word.lower() for word in words)
Explanation:
- Converts all words to lowercase (so “Python” and “python” are the same).
- Returns a dictionary-like object with counts.
To show the top 10 words:
for word, count in freqs.most_common(10):
print(f"{word}: {count}")
Step 6: Detect Long Lines
Now let’s find lines that are longer than the user-specified threshold.
def detect_long_lines(lines, max_length=80):
return [i + 1 for i, line in enumerate(lines) if len(line) > max_length]
Explanation:
- We return line numbers (1-based) for each line that’s too long.
enumerate()gives us both index and content.
Step 7: Display Everything Nicely
Let’s wrap up by printing all results cleanly.
def display_results(file_path, lines, word_count, freqs, long_lines):
print(f"\nAnalysis of: {file_path}")
print(f"Total Lines: {len(lines)}")
print(f"Total Words: {word_count}")
print("\nTop 10 Frequent Words:")
for word, count in freqs.most_common(10):
print(f" {word}: {count}")
if long_lines:
print(f"\nLines longer than threshold: {len(long_lines)}")
print("Line numbers:", long_lines)
else:
print("\nNo lines exceed the specified length.")
Then update main():
word_count, words = count_words(lines)
freqs = word_frequencies(words)
long_lines = detect_long_lines(lines, args.length)
display_results(args.file, lines, word_count, freqs, long_lines)
Final Code (All Together)
You can now paste everything into a file named text_analyzer.py.
import argparse
from collections import Counter
import string
def read_file(filepath):
try:
with open(filepath, 'r', encoding='utf-8') as f:
return f.readlines()
except FileNotFoundError:
print(f"File not found: {filepath}")
return []
def count_lines(lines):
return len(lines)
def count_words(lines):
words = []
for line in lines:
line = line.translate(str.maketrans('', '', string.punctuation))
words.extend(line.strip().split())
return len(words), words
def word_frequencies(words):
return Counter(word.lower() for word in words)
def detect_long_lines(lines, max_length=80):
return [i + 1 for i, line in enumerate(lines) if len(line) > max_length]
def display_results(file_path, lines, word_count, freqs, long_lines):
print(f"\nAnalysis of: {file_path}")
print(f"Total Lines: {len(lines)}")
print(f"Total Words: {word_count}")
print("\nTop 10 Frequent Words:")
for word, count in freqs.most_common(10):
print(f" {word}: {count}")
if long_lines:
print(f"\nLines longer than threshold: {len(long_lines)}")
print("Line numbers:", long_lines)
else:
print("\nNo lines exceed the specified length.")
def main():
parser = argparse.ArgumentParser(description="Command-line Text Analyzer")
parser.add_argument("file", help="Path to the text file")
parser.add_argument("--length", type=int, default=80, help="Max line length to check for long lines")
args = parser.parse_args()
lines = read_file(args.file)
if not lines:
return
line_count = count_lines(lines)
word_count, words = count_words(lines)
freqs = word_frequencies(words)
long_lines = detect_long_lines(lines, args.length)
display_results(args.file, lines, word_count, freqs, long_lines)
if __name__ == "__main__":
main()
Testing the Analyzer
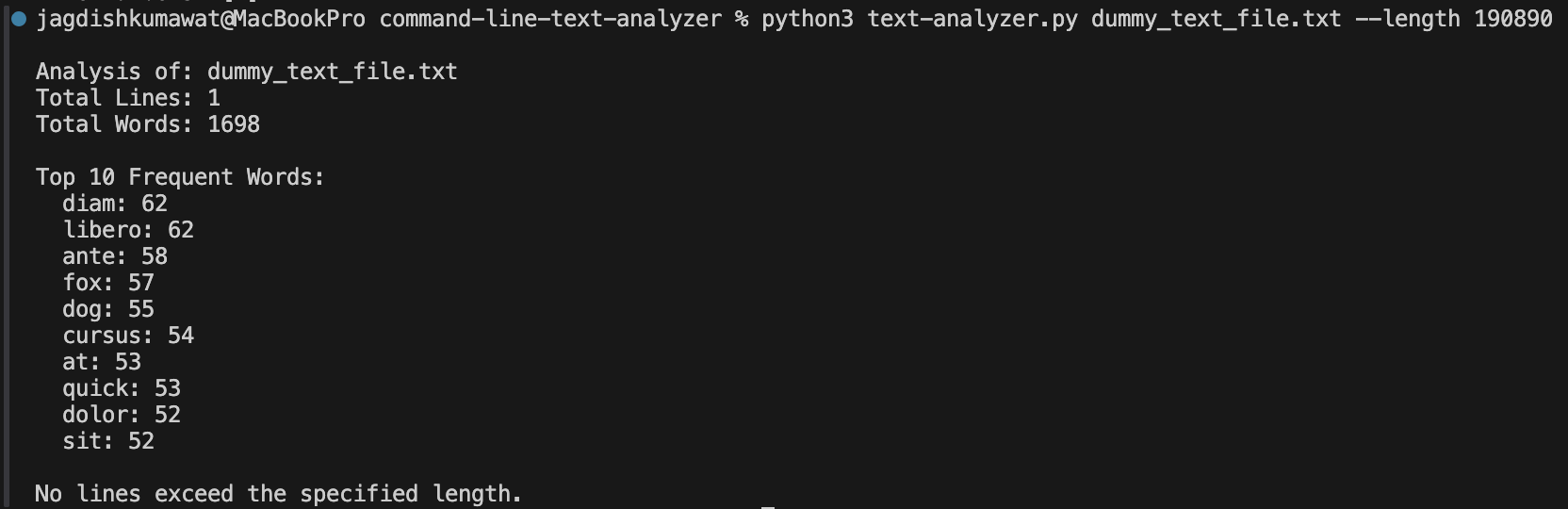
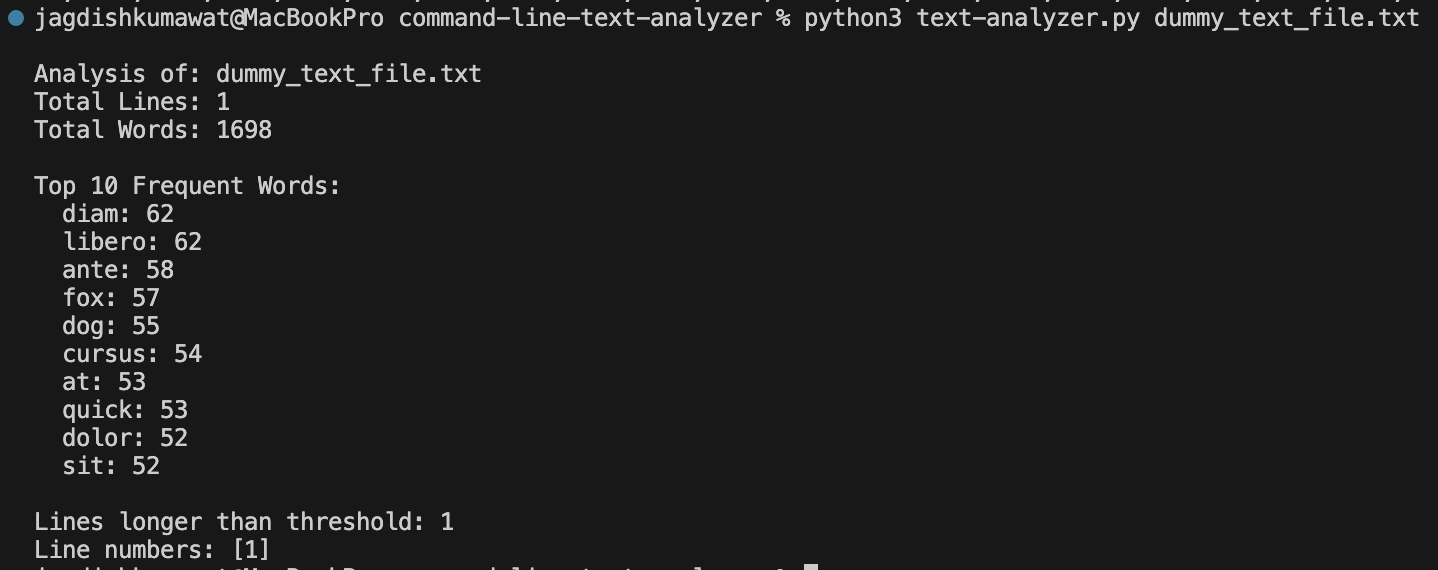
python text-analyzer.py dummy_text_file.txt
python text-analyzer.py dummy_text_file.txt --length 100
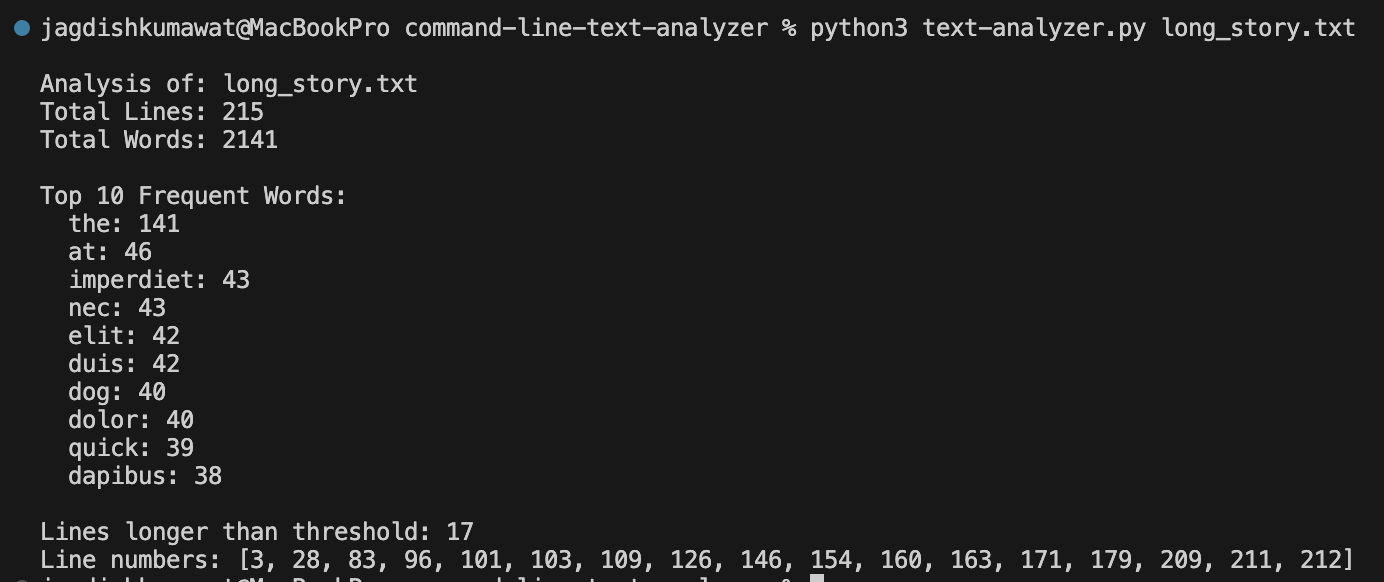
python text-analyzer.py long_story.txt
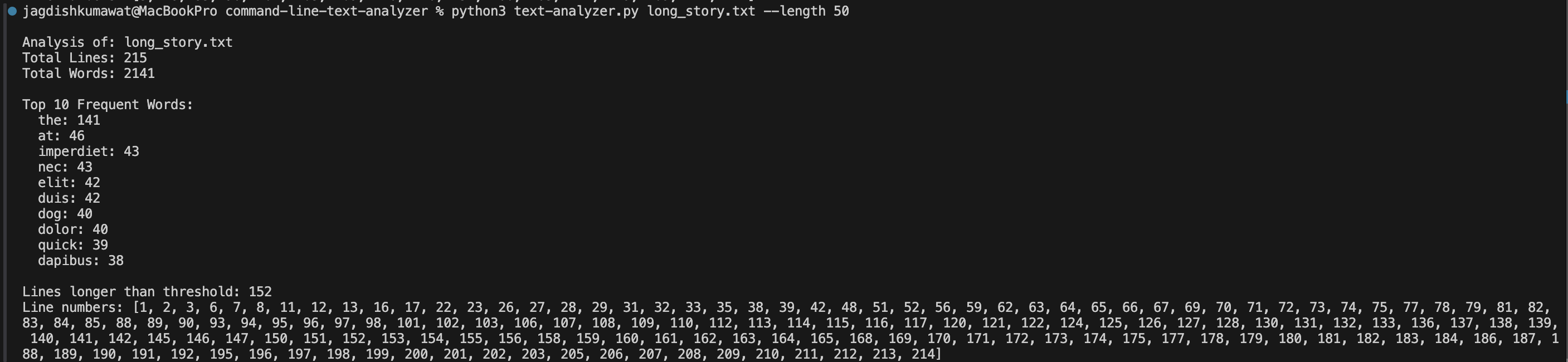
python text-analyzer.py long_story.txt --length 50
Conclusion
Congratulations! You’ve built a simple yet powerful command-line text analyzer in Python. This tool can help you quickly analyze text files, count words, and detect long lines.